 热点资讯
热点资讯


小初足交 95后,估值1000亿!马斯克、奥特曼背后的天才少年

如果要列出当下全球最有权势的一位95后小初足交,他的名字应该大多数东谈主都没外传过——亚历山大·王(Alexandr Wang)。
这位在硅谷被称为“下一个扎克伯格”的天才少年,在2022年借助着生成式AI的波涛,告成登上《福布斯》全球亿万富豪榜,也凭此成为了史上最年青的空手起家的亿万富豪。
尽管在一年后其创立的公司Scale AI因估值大幅下滑,他的名字也从富豪榜上隐藏。
但在本年5月,跟着Scale AI布告获取10亿好意思元融资,估值138亿好意思元(约为东谈主民币1000亿元),亚历山大·王也再一次回到寰球的视线当中。
从2016年创立到成为千亿估值的独角兽企业,亚历山大·王和Scale AI用了短短8年的时候,而凭借着Scale AI,亚历山大不仅在AI数据标注行业献技了一段传奇创业故事,也在全球AI激越中饰演了一个“卖铲东谈主”的脚色,为马斯克、奥特曼、扎克伯格等一众科技大佬提供数据支撑,某种进度上来说,他影响了所有这个词AI世界的神态。


“卖铲子”的天才少年
如果用一句话总结亚历山大·王的创业故事,那一定是一出场就手持爽文大男主脚本。
1997年,亚历山大出身于好意思国的新墨西哥州,其父母都是物理学家,在新墨西哥州洛斯·阿拉莫斯国度实验室责任。
对于亚历山大这个名字的由来,还有一个蕴含中国文化的故事:
Alexandr(亚历山大)是其名字的英文拼写,但比通用拼法少了一个e。在中国传统中,数字“8”承载着许多好意思好寓意,是以他的父母就想让他的名字刚好为8个字母。
受到家庭氛围的汲引,亚历山大从小就是“别东谈主家的孩子”:
小学时,亚历山大便展自大数学天才的一面,到了初中,亚历山大就读于顶尖私扬名校洛斯·阿拉莫斯,数次在好意思国数学东谈主才聘任赛中拿下铜牌、金牌等;
上了高中后,亚历山大又自学了编程技能,成为好意思国猜测机、物理、数学奥林匹克竞赛上的常客,得益均名列三甲;
此外,他9岁时学过小提琴,还精通华文、英语、法语等多种言语,不错说是“文理两吐花”。
除了学有所成,在高中时,亚历山大就收到了多家硅谷科技公司的责任邀请,他先是去了硅谷最热点的资产投资大数据不竭平台Addepar,之后又加入了“国外版知乎”Quora从事编码责任并担任技能专揽。
也就是在Quora,亚历山大褂讪了同为华侨的女孩Lucy Guo,后者也将成为Scale AI的纠合独创东谈主。

2015年,凭借优异的得益,亚历山大考入麻省理工学院(MIT),主要攻读数学和猜测机专科。笔据领英(Linkedln)的个东谈主贵寓自大,亚历山大在MIT肄业期间GPA为5.0(满分),且其选修的照旧商榷生级别的猜测机科学课程。
也恰是在其麻省理工学院上大一期间,DeepMind推出的AlphaGo,降服了围棋世界冠军,开启了东谈主工智能的元年和深度学习的激越。
“我记妥当时我在大学里,尝试使用神经收集,尝试稽察图像识别神经收集。我很快刚硬到,这些模子在很猛进度上仅仅数据的家具。”
亚历山大在背面一次采访中曾回忆起上大学时的想考,“这些模子或AI总体上是由三个基本支撑组成——算法、猜测才融合数据。”
在那时,也曾有公司在商榷算法,比如OpenAI或Google的实验室,或者其他一些AI商榷机构;至于算力,英伟达也已展示出了为这些AI系统提供算力的率领者后劲。
独一莫得公司专注于数据,亚历山大刚硬到跟着东谈主工智能技能的持久发展,数据贤慧变得越来越要害。
于是在麻省理工大一刚限度后的暑假,亚历山大决定从MIT辍学,与此同期Lucy Guo也从卡内基梅隆大学辍学,两东谈主一同创办了Scale AI。
那时许多东谈主为这两位天才的半途辍学感到痛惜,觉得这就是一场豪赌,但亚历山大的看法却不一样:“如果现在不肯意迈出这一步,那什么时候会得志呢?”
这里还有个流传的小插曲:
在大一限度后暑假的某一天,亚历山大跟爸妈说,我暑假搞了个名堂玩。
爸妈问到,啥名堂啊,送柠檬水照旧送外卖?
亚历山大讲演谈,差未几吧,搞了个AI公司,还有个叫Sam Altman的给我投了点钱,对了,airbnb(爱彼迎)亦然他们投的,现在估值也就300多亿好意思金吧。
除了拿到Y Combinator(山姆·奥特曼时任总裁)的天神轮投资,在创立第一年,Scale AI还拿到了风投巨头Accel的A轮融资。两方资助下,Scale AI初期的资金梗阻被扫清。
在竖立之初,亚历山大对ScaleAI的设想是打造一个一站式服务中心,惩办AI生态系统中的数据支撑问题。
因此,Scale AI早期的定位就是通过归拢自动化技能与东谈主力审核,创建一个高效、精准的数据标注平台,为创建机器学习算法的公司快速处理和标注大限制的数据集。
所谓的数据标注,是指为图像、文本、视频或音频等原始数据添加结构化信息,以便机器学习模子约略相识和学习这些数据的过程。
往常来讲,就是给你一段视频或图片,让你比物丑类地标出里面的行东谈主、车辆、建筑等元素,某种进度上,这是个小学生也能作念的事。
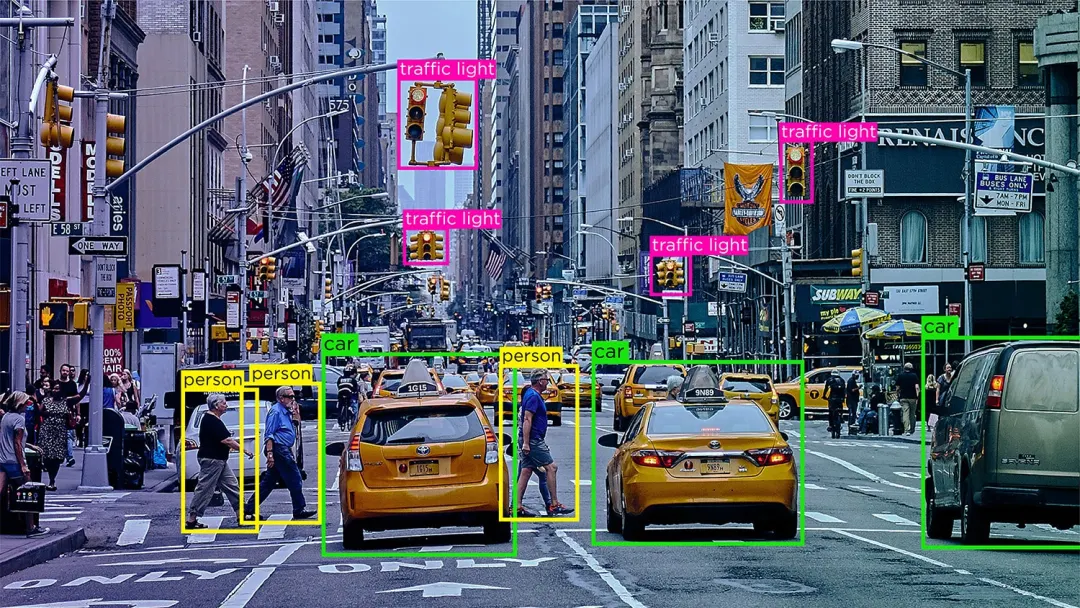
诚然旨趣很浅薄,但这些经过标注的数据对于东谈主工智能的发展弗成或缺。AI模子需要多数的标注数据来进行学习,才调具备识别、分类和预测等功能。
这里值得一提的是,尽管一些自动化器具不错加速部分标注过程,但为卓著到高质料、高精准度的标注数据,仍然需要多数的东谈主工来处理、标记和考据数据,尤其是在一些如医疗、自动驾驶、军事等对高精度有条目的领域。
事实上,在Scale AI崛起之前,数据标注行业在AI领域持久处于“旯旮”位置,其对多数东谈主工的需求使得外界打上了干事密集型产业的标签。
在大多数东谈主看来,数据标注行业既不“AI”,也少量都不“性感”。
但就是这么一个“低门槛”的“辛苦活”,被亚历山大在8年时候里干出了一家估值千亿的AI独角兽;在2023年《时期周刊》发布AI领域最具影响力的100个东谈主物中,亚历山大与李飞飞、黄仁勋、李彦宏等东谈主共同入选榜单,其本东谈主更是其中最年青的东谈主之一。
而在这背后,亚历山大又是提醒Scale AI怎样作念到的?

从0到估值千亿,
8年时候Scale AI作念对了什么?
尽管数据标注看起来是一个低门槛、干事密集型的行业,但在2016年的节点,它却是一个为数未几的空缺阛阓。
除了谷歌、亚马逊等少数大厂因业务需求成就了我方的数据标注部门外,大多数公司不肯意也莫得元气心灵去我方不竭,这导致标注数据的获取的过程耗时且崇高。
而这也恰是Scale AI“卖好铲子”迅速发展的契机所在,况兼再缅想Scale AI八年的发展历程,其告成也不错说是天时、地利,加东谈主和的一个后果:
1.天时
在创立Scale AI后,8年时候里亚历山大提醒所有这个词团队收拢了东谈主工智能行业发展的几次大风口。
先是自动驾驶领域。
2016年是AI时期的元年,也相同是自动驾驶周期的发轫,在那一年Cruise被通用以超10亿好意思元的价钱收购。
关爱到这一音讯后,亚历山大刚硬到自动驾驶行业对于数据标注将产生大限制的刚性需求——自动驾驶技能的发展依赖于多数高精度的标注数据,比如谈路场景、行东谈主和其他物体的图像数据,车企需要千千万万小时的视频数据进行标注来稽察和考据其算法。
“咱们构建了第一个支撑传感器会通数据的数据引擎,支撑2D数据和3D数据的组合,即激光雷达加录像头,这些开发装配在车辆上,这很快成为所有这个词行业的轨范。”
通过成就高效的数据标注平台,以及使用模子补助标注和数据预处理来加速了数据处理经由,使得标注成本和时候得到大幅度镌汰,很快Scale AI就招引了通用汽车、丰田和Waymo等车企的协调。
亚历山大和Scale AI也凭此在自动驾驶数据标注领域站稳脚跟。

而在2019~2020年期间,这个阶段自动驾驶行业技能方面已基本熟识,加上那时言语模子和生成式AI还未诞生,东谈主工智能领域处于一个高度省略情时期。
于是,亚历山大和Scale AI启动专注于政府把持,“这是一个彰着具有高度适用性的领域,况兼在全球范围内变得越来越要害。”
也恰是在进犯新阛阓的过程中,Scale AI也从畴昔单纯的数据标记延长到数据服务,提供从数据标记和不竭、模子稽察和评估,再到AI 把持开发和部署的全经由惩办决议。
在之后几年时候里,Scale AI在数据领域迅速崛起,客户也膨大到了医疗、国防、电商、政府服务等领域。
另外,为了应付某些行业数据不及的挑战,Scale AI还向卑劣延长到合成数据的生成,通过从现存数据中创建新的数据集,匡助稽察模子。
与此同期,Scale AI在这一阶段也启动死力于生成AI,与OpenAI开展协调,在GPT-2上进行RLHF的初次实验。
“那时的模子尽头鄙俚,确凿看起来不怎样样。但咱们觉得OpenAI是一群理智的东谈主,咱们应该与他们协调。是以咱们与发明RLHF的团队协调,并从2019年启动络续调动。”
2022年,ChatGPT的问世顾忌世界,生成式AI领域迎来了大爆发——生成式AI模子需要海量的稽察数据来进步其生成实质的准确性和万般性,加上大言语模子的爆发式增长极大推动了所有这个词行业对高质料标注数据的需求。
而靠着和OpenAI的协调,在生成式AI赛谈Scale AI已霸占先机,到了今天Scale AI更是成为了通用AI的数据锻造厂,为OpenAI、Meta、Microsoft等行业内险些所有主要的大型言语模子提供支撑。

2.地利
除了收拢这些行业风口到来的时机,亚历山大还借助着全球化这一地利上风,已毕了在数据标注行业里的成本最小化。
因为好意思国东谈主力成本欢快,在LinkedIn、indeed等平台上,数据标注的兼职时薪大多都在30-200好意思元之间,但动作一个干事密集型业务,这在客不雅上就条目企业去想考惩办数据分娩问题,或者采购关系服务。
于是在2017年,Scale AI 竖立了 Remotasks 动作其里面外包机构,在肯尼亚、菲律宾、委内瑞拉等地成就了几十家机构,辞世界各地培训了千千万万的数据标注员,这些标注员的责任大部分都是按件计酬,一次标注的收入低至几好意思分,许多合约工在时薪以至不到1好意思元。
曾有业内东谈主士指出,“Scale AI不是一家东谈主工智能初创企业,它仅仅一家提供低价劳能源的公司”。
但岂论外界怎样质疑,无法否定的如实,在这么的“全球工场”模式下,Scale AI的毛利率持久保持在65%以上,Scale AI也成为了当下AI领域为数未几不需要烧钱,而是狂赢利的AI初创企业之一。
2023年,Scale AI年化收入高达7.5亿好意思元(约合54.3亿元东谈主民币),预测2024年底将达到14亿好意思元(约合101亿元东谈主民币)。
3.东谈主和
除了营收快速增长,创业8年时候,亚历山大和Scale AI的背后还聚集了一支豪华的投资东谈主队列。不仅有着泰半个硅谷圈大佬,也出现了亚马逊、英伟达、英特尔、Meta等超等大厂。
在前文咱们提到,Scale AI刚创当场,就诀别获取硅谷驰名孵化器Y Combinator和风投巨头Accel的支撑,前者的时任总裁山姆·奥特曼在背面的OpenAI又与Scale AI 开展了协调,此后者机构的搭伙东谈主还曾将家里的地下室借给Scale AI临时办公。
而此后5、6年时候里,Scale AI也基本是一两年就融一次资,而参与投资的机构和个东谈主在这个过程中彰着也不啻是进行资金上的匡助,更是在多方面都进行了助力。
2024年5月,Scale AI再次官宣完成F轮融资,融资额10亿好意思元,估值增长跨越80%至约138亿好意思元(约1000亿东谈主民币),投资方威望号称史诗级豪华,20多家机构和个东谈主:
老推动Accel领投,Index Ventures、Founders Fund、Coatue、Thrive Capital、Spark Capital、老虎基金、Greenoaks、Y Combinator、Wellington Management和GitHub 前首席推行官 Nat Friedman接续加码,同期英伟达、Elad Gil、亚马逊、Meta、想科、英特尔、AMD、DFJ Growth、WCM、ServiceNow Ventures也参与了这次融资。
时来世界王人同力。毫无疑问,动作这一波AI波涛中的“耀眼群星”中的一颗,亚历山大和Scale AI注定要留住浓墨重彩的一笔。
也正如亚历山大在完成F轮融资后在采访中讲到的:“Scale AI为咫尺阛阓上险些所有起初的 AI 模子提供数据支撑。借助这次融资,公司将干涉旅程的下一阶段——加速丰富前沿数据,为通用东谈主工智能铺平谈路。”
而惩办东谈主工智能的数据问题将是他一世为之奋斗的行状。


中国为什么莫得Scale AI的诞生?
事实上,看完Scale AI的发展故事,大多数东谈主可能会产生的一个疑问是,为什么中国莫得雷同于Scale AI这么的企业诞生?
尤其是在生成式AI激越前,国内的东谈主工智能行业在把持方面一度起初,况兼数据标注动作干事密集性企业,中国自然就有上风。是以为什么呢?
总体来看,这背后有几方面的原因:
1.“资源陷坑”
欧美成人在线播放这里先引入一个“资源陷坑(是曲)”的想法,什么是资源陷坑,就是指一个国度或地区领有丰富的当然资源,但因为过度依赖这些资源,刻薄了其他潜在的经济增长领域,如制造业、服务业和技能调动等,导致经济发展单一、结构不对理,同期跟着这种当然资源贫困或阛阓需求下落,经济可能会碰到严重打击。
典型的例子即是委内瑞拉、俄罗斯,它们依靠石油、自然气等赚取多数的外汇,但除了能源行业外,其它的经济产业都尽头过期,这种国度也被称为“资源是曲型国度”。
一定进度上,在AI数据标注行业,国内也堕入了这种资源丰富的“是曲”。
事实上,国内的数据标注业务也很早就起步发展了,但并莫得造成限制。许多龙头企业诚然竖立了数据标注部门,但主如果为自己业务服务,而并不是寻求将数据与各个行业进行资源匹配;
加上依靠国内的东谈主口红利,让标注后的数据获取成本变得十分便宜,哪怕是今天堂内的数据标注价钱依旧偏低,拿重庆这种新一线城市来说也仅为4~6k/月。
在这种情况下收受技能平台或者进一步研发来提高数据标注或是从标注行业进一步朝上延展调动,对于处在阛阓竞争中的企业而言,可能反而是收之桑榆的作念法。
但一朝在这个阶段错过了对数据标注行业的技能调动或千里淀,也许就恒久地错失了调动升级的契机了。
2.生态不及
这里的生态不及体现在两个方面,一是单纯从言语生态来讲,必须要承认,英文的使用范围是全球,而华文的使用范围更多照旧在国内以及国外的部分华东谈主。
是以在数据标注这一产业上,Scale AI自然就有了上风,站在成本的高地,在全球范围内寻找着价值凹地,而国内哪怕是有东谈主口红利,这成本上风终究更高,且在成本(投融资)方面也莫得占据高地。
另外,需要提到的是在数年前,跟着迁徙互联网神态的熟识,国内互联网生态在那时也进一步走向了抵拒闭塞,而这也使得数据在流畅上出现了阻滞,以至不错说那时的数据标注行业也被动参与到这种抵拒闭塞的生态中去,各为其主、各自而战,无法造成灵验的、限制性的调动力量。
3.视线局限
对于数据标注行业,站在那时阿谁节点,只消少数东谈主能因为确信而看见。
在国外,也只消亚历山大等寥寥几东谈主,在国内这么的东谈主彰着就更少了。
事实上,大多数参与到数据标注行业中的东谈主,更多就是秉持着过往的干事密集型产业的逻辑,靠着“内卷”来已毕糊口以及盈利的。
然则亚历山大不同的是,尽管行业逻辑是干事密集型的脾气,但对于他而言,这仅仅最基础的少量,是动作构建起所有这个词数据行业凹凸游生态的一个跳板。正如其在最近的访谈中谈到,东谈主们也曾用尽了互联网上的所有数据,想要开发出比GPT-4.5更开阔的东谈主工智能,则必须构建前沿数据。
所谓的“前沿数据”是指那些与把持场景密切关系、能实时反应最新趋势和变化的数据,通常包含多数长尾或有数的场景,有助于进步AI在非典型情况下的说明,推动东谈主工智能才调的范围向复杂推理、多模态等主义发展。
跟着AI的快速进化,明天的数据稽察需要更多地与特定任务、特定把持场景相匹配,因此也需要挖掘和分娩出更多新的、互异化的数据,而这可能也恰是亚历山大在2016年时就看到的明天。
从这个角度来看小初足交,Scale AI动作一面镜子,其从最“低价”的行业中成长为一个估值千亿的AI独角兽企业有太多不错学习的处所了。